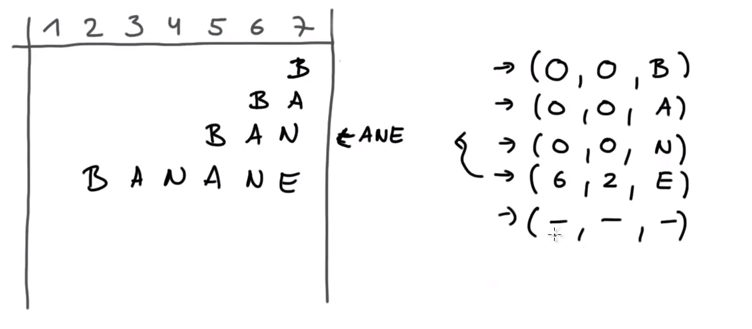HTTP2学习(五)—HTTP2 VS SPDY
SPDY是HTTP2的催化剂,但SPDY不是HTTP2。
本文主要针对SPDY与HTTP2之间的区别,而不太多的涉及它俩之间与HTTP1.X的区别。
SPDY的出现
SPDY是谷歌在09年年中时发布的,它的主要目标时通过解决HTTP1.1中一些显著的性能限制,来减少网页额的加载时间。目前为止,Chrome,Firefox和Opera都支持了这一协议。
SPDY引入了新的二进制分帧层,以实现多路复用、优先次序、最小化的消除网络延迟,同时对HTTP首部进行压缩,减少HTTP报文的冗余数据。
目前为止,我们只在实验室条件下测试过 SPDY。最初的成果很激动人心:通过模拟的家庭上网线路下载了 25 个最流行的网站之后,我们发现性能的改进特别明显,页面加载速度最多快了 55%。
——A 2x Faster Web Chromium Blog
一方面由于随着web应用的发展,HTTP1.1协议的局限性突显的越来越严重,另一方面由于SPDY的优秀表现,12年初,W3C向全社会征集HTTP2的建议,最终决定将SPDY规范作为制定标准的基础。
随后的时间内,SPDY与HTTP2共同进化,HTTP2提出新规范或新功能,SPDY为它进行测试和验证。当HTTP2一切就绪之日,就是SPDY退出舞台之时。事实上,在今年2月谷歌公司已经宣布将在16年年初放弃对SPDY的支持。
目前各浏览器对SPDY和HTTP2的支持情况分别如下: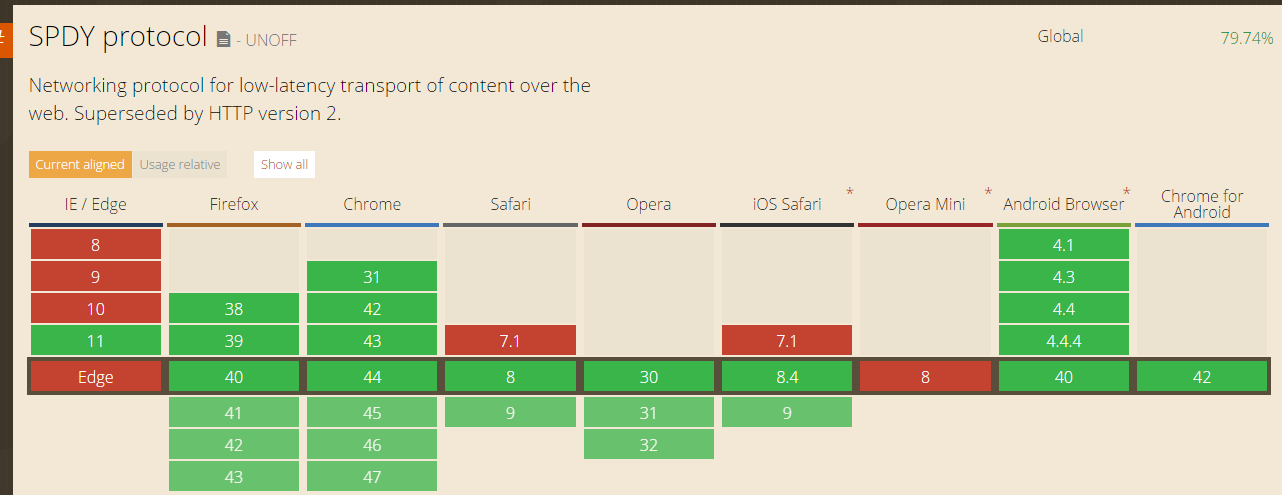
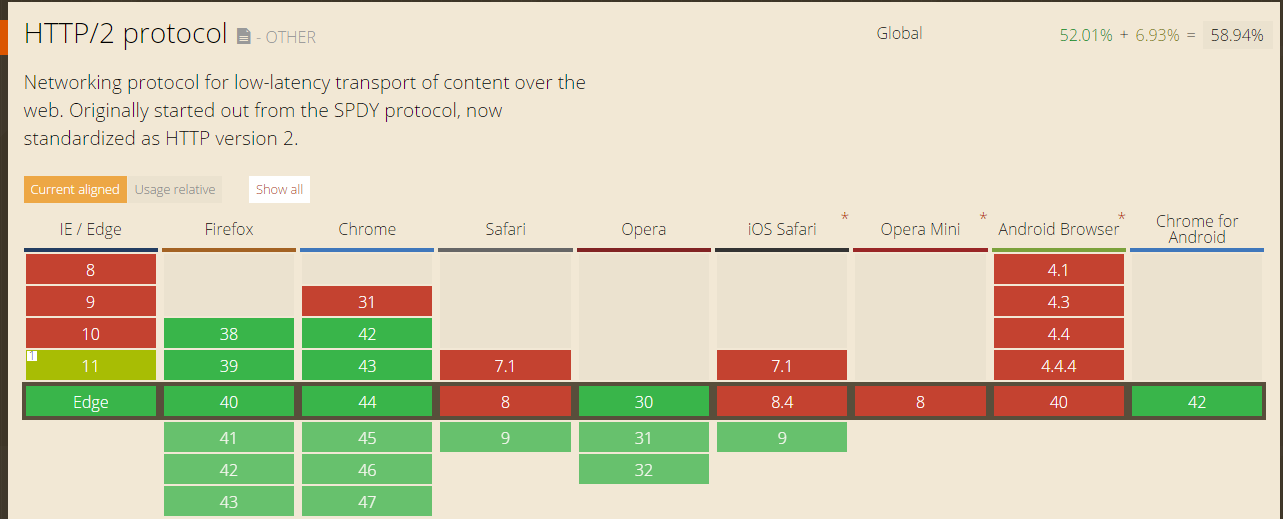
SPDY与HTTP2的区别
- 头部压缩算法,SPDY,通用的deflate算法[注1];HTTP2,专门为压缩头部设计的HPACK算法
- SPDY必须在TLS上运行,HTTP2可在TCP上直接使用,因为增加了HTTP1.1的Upgrade机制
- 更加完善的协议商讨和确认流程
- 更加完善的Server Push流程
- 增加控制帧的种类,并对帧的格式考虑的更细致
注
- deflate算法
这个算法是由2个算法组合而成,哈夫曼编码和LZ77编码。
哈夫曼编码
一种无前缀编码,简单来说就是长字符串用短编码表示,以最终达到减少总大小的目的。具体编码过程可参考Huffman 编码压缩算法
例如,在一篇英语文章中,字母“E”出现的频率最高,“Z”最低,如果我们采用字符编码,那么每一个字母都是8bit表示;但是如果,我们使用不定长的bit编码,频率高的字母用比较短的编码表示,频率低的字母用长的编码表示,就会大大缩小文件的空间。
大致思路:每次总是选取频率最小两个节点,将其频率相加,最终构成一个最优二叉树。
例如:有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1,那么我们第一步先取两个最小权值作为左右子树构造一个新树,即取1,2构成新树,其结点为1+2=3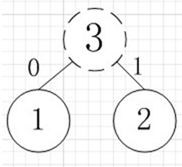
虚线为新生成的结点,第二步再把新生成的权值为3的结点放到剩下的集合中,所以集合变成{5,4,3,3},再根据第二步,取最小的两个权值构成新树,如图: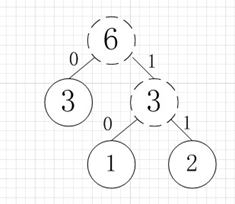
再依次建立哈夫曼树: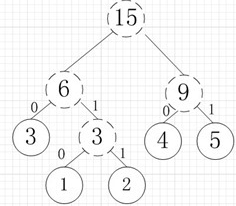
其中各个权值替换对应的字符即为下图: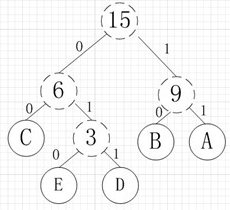
所以各字符对应的编码为:A->11,B->10,C->00,D->011,E->010
LZ77编码
字典压缩算法,用到的场景比如gzip。具体算法可参考,须翻墙
这个算法的主要思想是:文件中有两块内容相同的话,那么只要知道前一块的位置和大小,我们就可以确定后一块的内容。所以我们可以用(两者之间的距离,相同内容的长度)这样一对信息,来替换后一块内容。由于(两者之间的距离,相同内容的长度)这一对信息的大小,小于被替换内容的大小,所以文件得到了压缩。
大致流程如下:
可构想出2个窗口,一个作为搜索缓存区(已完成搜索的字符),一个作为待搜索窗口。如下图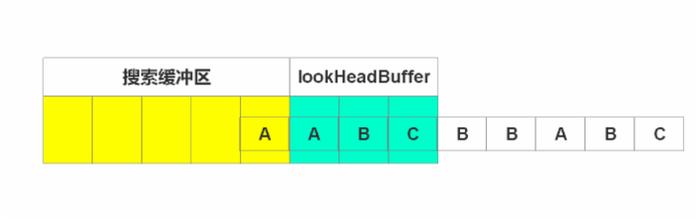
编码过程:
- 如果待搜索字符c没在搜索缓存区中找到,则输出(0,0,c),同时,整个窗口向前移动1位
- 如果待搜索字符c在搜索缓存区中找到,起始位置在搜索缓存区中x,连续长度是offset,待搜索窗口中offset之后的一个字符是d,则输出(x, offset, d)。之后,整个窗口向前移动offset位。
- 最终输出的三元组就是压缩码
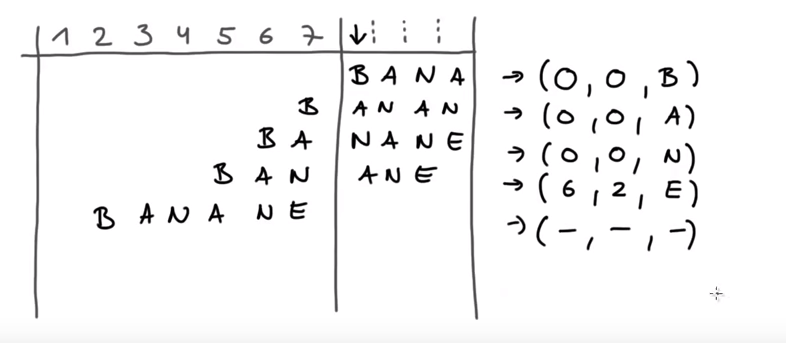
解码过程: